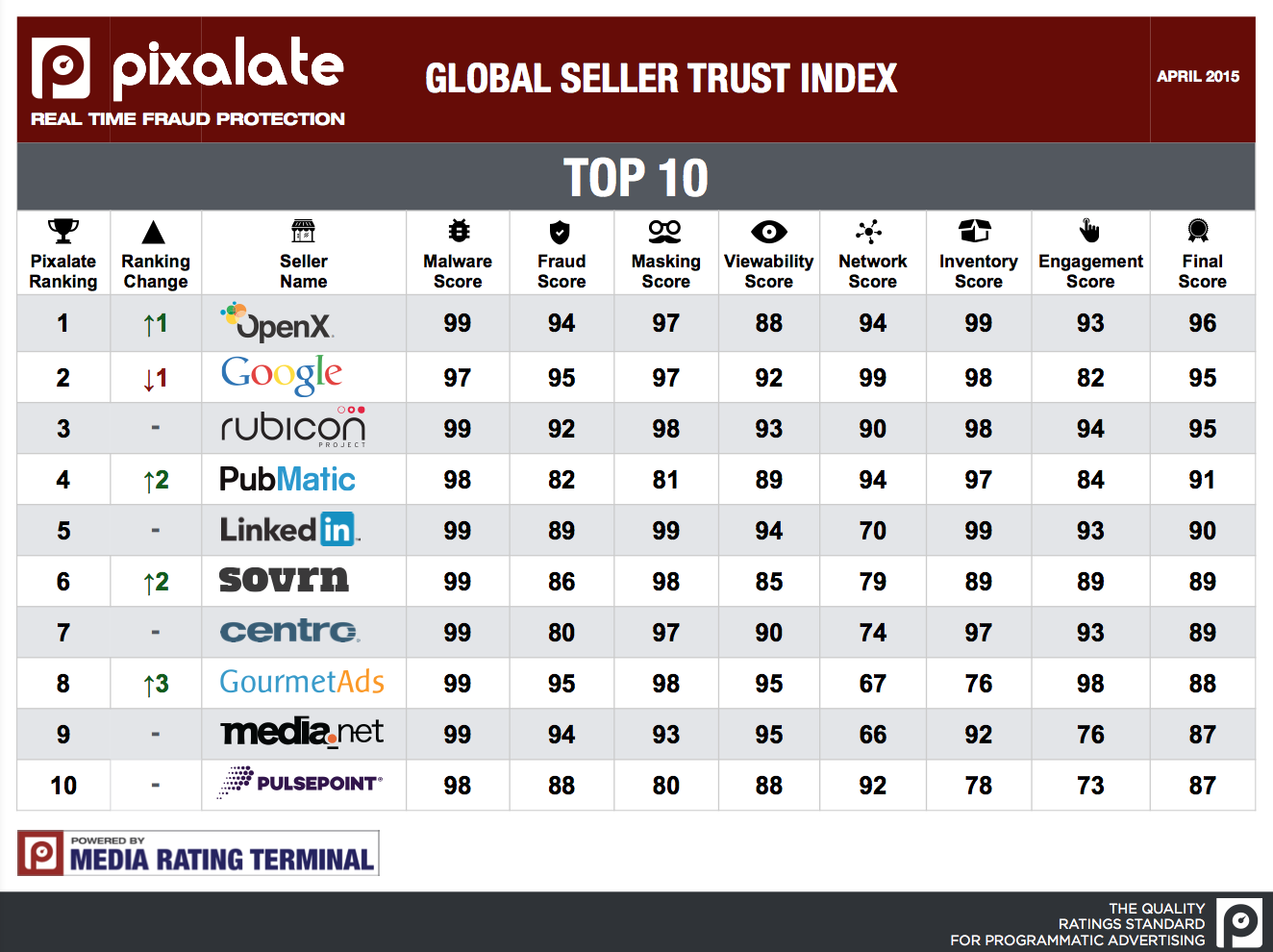
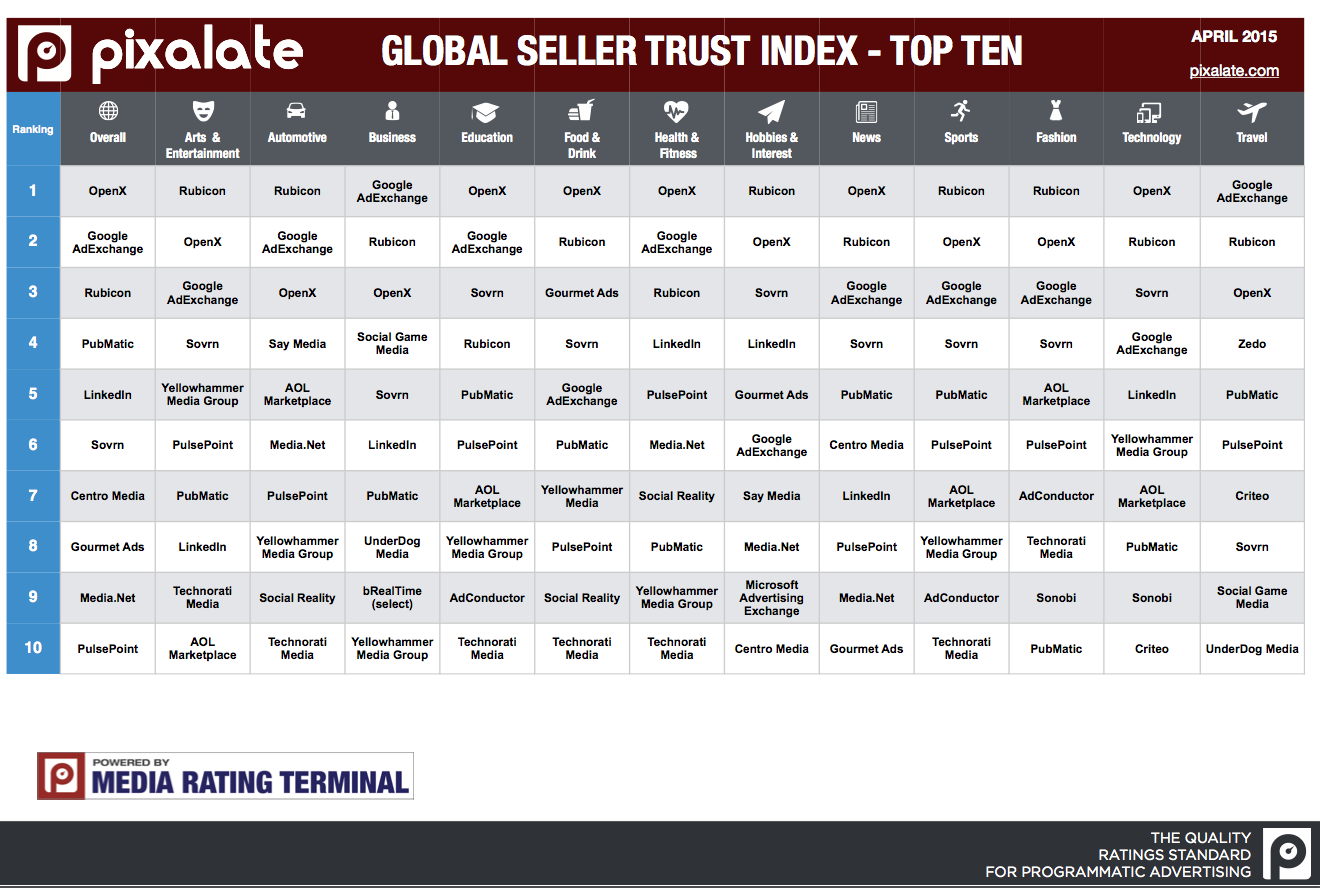
In today’s digital ad market, geotargeting depends on mapping a user’s IP address to a physical location, a task every ad server outsources to my knowledge. This is because the process of assigning a geographic location to an IP is messy and complex to say the least. Just because the ad server outsources the functionality however doesn’t give Ops an excuse to ignore this important and highly utilized feature.
How is an IP Address Associated with a Geographic Location?
By and large, IP addresses are arbitrary – meaning they could be anywhere, and there isn’t much rhyme or reason to their values from a geographic perspective. It isn’t as though if the IP address starts with a 1 it is always located in the United States, for example. Instead, companies like Digital Envoy use a multi-layered approach to assign geographic qualities to a user, some highly technical, and some which are just common sense, and some that are a combination of the two.
On the common sense side, a fair amount of geolocation companies can leverage Regional Internet Registries, or RIRs, to assign high level qualities, like country or continent. The RIRs each own dedicated ranges of IP values and exist to allocate IP addresses within their regions, and cooperate among each other to ensure that the same IP isn’t being used in more than one place. So placing the IP address within a specific RIR’s range allows the service to identify location at a very high level. Some geolocation services are rumored to work with large registration based sites as well, and have zip code information that a user might manually enter during a sign up process.
Pings, Traceroutes, Reverse DNS, and Other Technical Methods of Geolocation
From there though, the heavy lifting is usually done through a combination of three technical processes known as pings, traceroutes, and reverse DNS lookups. Let’s run through a high level explanation of all three processes, and then explain how they work in concert to geographically locate a single IP address.
A ping is just a small piece of information sent from one computer to another, with a request to call the originating computer back. Pings can also record the round trip time of the journey, and are used for a variety of administrative network processes. Think of it like a submarine’s sonar technology, applied to the internet.
Tracerouting is basically a way to record the network routing process of the ping service, or the detail behind how the ping got from one machine to its destination. Tracerouting records how a ping is routed, who it is routed through, and the time it takes at each step. When information travels across the internet, be it a ping or just regular surfing, it moves through a series of very high speed fiber optic networks owned by various public and private entities. Now, when the information gets physically close to a user, it passes down to an Internet Service Provider (ISP), which sells internet access to consumers. The ISP eventually moves the packet of information to a nearby network router to the user, which connects directly to the user. By using the traceroute utility, the geolocation service can know every system the information was passed through in order to get to its final destination. The important piece of information the service gets from a traceroute is the IP address of that final network router, geographically nearest to the user. You can ping or see the traceroute command in action on your own machine at Network Tools.
With the network router’s IP address in hand, the geolocation service can finally use a technique known as a reverse DNS lookup to identify who owns that network router, which it can use to lock in on the physical location of the user. Reverse DNS is simply a service to identify the hostname of an IP address, that is, who owns an IP address. For many home computers, the host ends up being the ISP. For businesses, the host ends up being the company’s domain. DNSStuff provides a reverse DNS lookup service – just enter an IP address into their ‘IP Information’ tool to try it out.
Geolocation in Action
Now that you understand the basic approach, here’s how it all works together at a high level –
When a geolocation service wants to triangulate an IP, it starts by pinging that IP address from a central server it owns, and then looking at the traceroute. From the traceroute, the service can identify the nearest network router to the user by IP, labeled point A on the diagram below. Then, using a reverse DNS lookup, the service can find out which ISP owns that router, and then query the location from public data, the ISP itself if the service has a business relationship in place, or failing that, triangulate the location with the process below.
In all likelihood, the geolocation service already knows the location of this network router, either by working with an ISP directly, or through previous triangulation efforts. With that location in hand, the geolocation service hands off the triangulation process to servers closest to that network router, of which it also knows the exact geographic location. Now, the service sends a ping from at least three of its own separate servers (1, 2, 3), and records the time it takes to reach the user. Only time can be recorded from a ping, not distance, but using time as a radius, the geolocation service can draw a circle around each server, and know that the target location must exist at some point on the arc.

With three separate locations, the target location should exist at the one point where all the arcs meet, which also gives the service the exact vector to the target from each server. And, since information runs through fiber optic cable at a known, constant speed (about 2/3 the speed of light), the service can now translate that time into a distance, and with the vector and a known server location, calculate the exact location of the target, within a certain margin of error, depending on the exact method used, and how many points of triangulation are employed. Currently, the most advanced geolocation triangulation methods employ as many as 36 points to eliminate problem data and increase accuracy, and can accurately map an IP address within 700m – but we’ll talk more about that in the final piece in this series.
Network Maps & WHOIS Lookups
Using either piece of information, the ISP or the business domain, the geolocation service can further refine the geographic values of a given IP. Geolocation services may also work directly with ISPs to get the general physical location, when available of a given IP, since the ISP will know the exact address of the customer using that connection at any given time. It’s important to note that no PII is exchanged in that process, a zip code is just mapped to the IP address, and not all ISPs participate, or may simply provide the location of the final network router instead of the end-user’s zip.
Some of the more sophisticated geolocation services may be able to deduce the physical location of an ISPs network routers, also known as the ISP’s network map, by pinging those routers from various servers with known geographic locations, measuring the time it takes to get a response, and using that information to triangulate the router.
Businesses may also have a specific address, available through a WHOIS lookup, which allows country, state, city, and zip to be assigned. The WHOIS directory is a public registry of who owns what domain, along with their name, and importantly, address. Through this information, geolocation services can get a better idea of the physical location of each machine.
Where Does Geolocation Data Come From?
In most cases, a 3rd party table from a company that specializes in geolocation data. Practically speaking, most of the advertising industry relies on a small company called Digital Envoy, founded in 1999 by a few smart entrepreneurs, and was acquired by a larger media company called Dominion Enterprises in 2007. Digital Envoy pioneered the process of linking an IP address to a geographic location, and specializes in keeping the information current, and accurate.
Effectively, Digital Envoy maintains a massive table of literally billions of IP addresses and their inferred geographic qualities, and then sells access to that table at various levels of granularity to ad servers and lots of other companies who have an interest in identifying the location of a user, an ad server for example, who then cache the information in their local database, and can run queries against it.
Other companies that perform this service include Quova, MaxMind, GeoBytes, Cyscape, IP2Location, andAkamai’s EdgeScape product, though there are also free services out there such as HostIP, IPInfoDB, andSoftware 77.
[This article was originally published on Run of Network in Dec of 2011]